

crazy how as soon as mozilla does good stuff nobody is there
We’re all glad to see Mozilla have a win, at least I assume so. But there’s been a lot of other much bigger decisions that have gone on recently that make us (at least me) hesitant to celebrate at the first good thing.
On the more technical side of things they are doing excellent work, it’s on the bike shedding department that the overpaid management is doing idiotic choices.
as always on these corporations
Yeah it’s like the fucking Goat thing. Mozilla fucked a goat and shocked that that’s all people remember.
I dunno, finally getting vertical tabs is not exactly making me hesitant to celebrate, quite the opposite. Someone at Mozilla must have been a portrait-mode desktop monitor user, can’t understand the years-long resistance to this otherwise.
I think its very stupid that so many people criticize mozilla for engaging in ai.
Ai is the future.
I think people fear it being an annoying default they can’t switch off, instead of the useful supplement it currently is.
Many also fear that it will lead to misunderstanding and rampant misinformation. Which at the current trajectory is not an unreasonable fear.
If AI summarization becomes uncomfortably popular, I hope реοριe bеgiи цsing меtноds tо bгеαk iτ, whеп thегe is sомe imрoгtαиt inГогмαtiοn γоυ doи"t шαnt sцмmaгizеd, dυе tо рσteпtiаΙ foг мissrергeseпtатiοη bγ βαd sцмmагizαtiои Ьγ thе ΛΙ. ΜаγЬe sомeοηe сåп mаκе α tоοl tо do tнis αutοмаtiсаIly, siпсe it is tеdiоцs tο dø ît mаиυαIIγ.
(This comment is a demo on how that can be done.)
I’m quite a big fan of perplexity AI, which shows you sources it used to generate the answers. One thing I often do is type a question, glance the automated answer and then jump to the source to see what the users said (basically I use it like a tailored search engine)
Admittedly, there’s nothing stopping the company from throwing up fake sources to “legitimize” their answers, but I think that once models become more open (e.g. AMD’s recent open weights addition is an amazing leap forward) it will be harder to slip in fake sources
Sounds like a search engine with extra steps. Kudos to them for removing one of the extra steps, which would usually involve going to a search engine and then finding and vetting sources anyway… AI appears, to me, to be nothing but a rough draft generator that requires both input from a human and output with the draft it creates.
I agree with that assessment, and tbh I’m happy for it
Email and message summarization also introduces new problems that don’t happen when using a chatbot for questions and answers since through the process of summarization it removes information from the original text and may remove key information or mischaracterize the message. The ways it may do this stuff isn’t exactly predictable either. It’s also harder since it’s not about proving that something is true or not based on outside sources, it’s about it being accurate to what they said, which may not be provable to outside sources.
I’ve found summarization to be relatively trustworthy. Perplexity does not appear to hallucinate much, and on the odd occasion it does, I dive into the sources it provides.
There are tools that do this using replacement and/or zero width characters.
卄乇ㄥㄥ ㄚ乇卂卄 乃尺ㄖㄒ卄乇尺
Wоw thаոk yоu sо muсh, thіs іs еvеո bеttеr thаո whаt і wаs ԁоіոg, іt lооks muсh сlеаոеr tоо. Wоulԁ bе hаrԁ fоr реорlе tо tеll whаt іs gоіոg оո аt fіrst glаոсе.
Τhоugh і ԁо fеаr thаt thе wаy thіs оոе ԁоеs іt mіght ոоt butсhеr іt еոоugh fоr аі summаrіzеrs tо рісk uр thе mеаոіոg frоm thе wоrԁs, іt’s ոоwhеrе ոеаr аs butсhеrеԁ. Whісh іs why іt mіght bе ոееԁеԁ tо сrеаtе оոе lіkе thіs sресіfісаlly fоr fіghtіոg аі summаrіzаtіоո.
Don’t you think it’d be pretty easy to teach it to still be able to read it?
AI might be the future but certainly not like we’re currently doing it, it’s like saying “electric vehicles are the future” when you’re only referring to cars.
The Mozilla foundation also granted some money to ente a company that offers Google photos replacement with end to end encryption.
Anyone used Ente? How is it?
i downloaded it after the news the other day. Presently uploading >200gb of pictures.
Android App has a few quirks, not very snappy, but it looks pretty polished.
The on device ML seems to be pretty accurate once you start tagging people.
We’ll see how it handles me throwing the 200gb at it because it was already stuttering a bit when scrolling through ~15gb of pics.
I havent had the chance to spin up an immich instance yet to compare the two.
All in all, we might need to wait for a longer term user to chime in, but as of now to me it seems good enough.
Edit: 2 weeks later. I installed immich on a proxmox node with a rtx 2060 super passed through. it flies compared to ente, which is to be expected as immich isnt e2ee. I will most likely maintain both libraries for now, but Immich is definitely a more complete product.
But… Immich does this just fine, and is pretty great at it.
Options are good
This
One of these is proprietary, so one option is good
Not everyone has the technical ability or hardware to selfhost immich, even just for LAN access. If I tried to teach my wife enough about docker/docker-compose to get immich set up, running, kept updated, and troubleshooting when it has problems… I would probably be limping away with a fork stuck in my leg. Could it be a fun project for people that are interested in it? Definitely, but most people want an easy cloud service that works as easily as data-gathering alternatives over something they have to maintain themselves even in the form of occasional docker-compose pull
I think I’m going to wait until immich thinks so as well
I have self hosted immich almost a year, tried to make it the standard for my family. For me it was a pain in the ass to keep it running and available to have a smooth experience on my family. I had to rebuild it several times because of complex behavior and a few breaking changes, the iOS app is not working properly, I ended up removing it, too much time consuming.
Yeah, Immich has been on my radar for a number of years, but I’ve read a lot about breaking changes being a pain to deal with, and I’m a bit busy as it is right now with work and other personal projects to tinker too heavily.
Will take a closer look as I hear a stable release is planned soon.
I’ve been running mine for a year or two and don’t really mess with it at all. I think I remember those breaking changes maybe 18 months ago? Was not difficult to update, and it’s been running smooth as butter since.
Personally I don’t trust myself with self-hosting something as important as photos. It would probably be fine, but I’m willing to pay for someone else to manage the infrastructure.
Backups. You should be taking regular backups whether it’s you hosting or Google. If you are, there’s really very little risk.
You’ll also have the images on the phone, which should remain long enough for the images automatically stored to get into backup storage. Personally, all my images upload from my phone automatically after I’m on WiFi for 10 minutes.
This is a betrayal of Lord Immich’s good name and estate.
Very happy Ente user here! It’s a great alternative to Google Photos and Immich (since I think photos are too important to self-host).
They have an easy guide for migrating from Google Photos (basically they can import a Takeout export directly).
https://ente.io/faq/migration/from-google-photos/
I’ve got it installed on my phone with automatic backups enabled. It had no issues with duplicates from both Takeout and the existing photos on my phone. (I even did the upload twice due to running out of space the first time, and there were no dupes). The app has a pretty similar design to Google Photos, so it feels familiar. It also supports Google’s version of “live photos”.
You can create links to share albums or individual photos, and you can also add people to your plan.
I enabled the local machine learning analysis and, while it’s not perfect, it does make for a pretty nice searching experience.
Pretty good, very responsive to feedback on Matrix/discord. Great features, love it
We already have Immich though
Okay and? Immich is good but alternatives are always good.
If I’ve learned anything from this community, it’s that having just one open source alternative to a closed source POS run by Google is not the ideal! Competition is always healthy.
More options is good.
deleted by creator
Yes, that’s how it works. If you do bad stuff, people leave. They are no longer around to notice if you do good stuff.
Lemmy sure loves a circlejerk about shitting on Firefox.
I love my Firefox and no amount of downvotes could change that lol
I love firefox to, but when a loved one starts hurting themselves and those around them you need to set healthy boundaries or you will be hurt.
People aren’t shitting on Firefox, people are shitting on Mozilla and rightfully so. Mozilla has made many bad decisions, decisions that may call into question the future of Firefox and whether their decisions will compromise it as a privacy friendly browser. After all if Mozilla starts making changes which are harmful towards privacy and hard codes them into the browser, there’s no getting around that with user.js tweaks, that requires more work to fix.
Thankfully there are forks of Firefox but since those depend on the upstream from Mozilla the more they change the harder it is to undo those changes. A manifest V3 style change (which isn’t happening now but could happen in the future if they get into advertising), would be devastating, because even if Librewolf can undo those changes, it’s very likely they would have to implement their own extension distribution system because AMO would very much reject incompatible add-ons in that scenario.
So yeah people do have the right to criticize Mozilla in this regard, this trend has happened before, it will continue to happen in the future. Enshittification is a slow and ugly process, best to catch it in the early stages than to wait it out until you’re already boiling (frog boiling analogy).
This post is about how Firefox needs to be loved more and it has over 500 upvotes, I think Firefox still has plenty of circlejerk potential on Lemmy
Firefox is the one enshitting themselves not us.
Isn’t this the same as “Total Cookie Protection” that was released a while ago?
Yes and no, total cookie protection prevents cookies from loading from other sites, CHIPS is a new standard that makes it so that that is impossible* to begin with. (simpifying here but thats the idea)
*unless the browser allows it
my impression was that it was impossible already, because there was effectively a different cookie storage for every site
oh
https://developer.mozilla.org/en-US/docs/Web/Privacy/Privacy_sandbox/Partitioned_cookies
CHIPS is similar to the state partitioning mechanism implemented by Firefox. The difference is that state partitioning partitions cookie storage and retrieval into separate cookie jars for each top-level site, without a mechanism to allow opt-in to third-party cookies if desired. As browsers start to phase out third-party cookie usage, there are still valid, non-tracking uses of third-party cookies that need to be permitted while developers begin to handle this change.
so this adds a setting to allow a site access to shared 3rd party cookies, when the site supports the feature?
Based on Mozilla’s documentation, it looks like CHIPS only applies to “cross site” cookies that are just accessible on different subdomains of the same site. A third party cookie could share data between a.site.example and b.site.example if it asked nicely, but not on site2.example.
If this isn’t about it subdomains exclusively, it’s not apparent to me. But it’s all pretty confusing, and CHIPS appears to be just one minor thing that Google introduced when they were creating Privacy Sandbox back in 2022. (You know, to facilitate the total removal of third-party cookies, something they eventually backtracked on anyway.)
You can embed bits of a website in other websites, that’s how 3rd party cookies exist
A toot?
The mastodon version of a post or, sadly, tweet.
It’s, uh, not the best name.
But maybe, just maybe, it more appropriately attributes correct value to a social media thing. ;)
Most people these days refer to them as posts, toots is older Mastodon linguo.
Etymologically, I think the word “tweet” was slowly being supplanted by “post” even before Twitter’s name was officially changed to X. After all, “post” is universal, and there were many uses of thingposting that go back years, even on Twitter itself.
When Twitter launched, they used “post” instead of “tweet”. Tweet was a word created by the community.
TIL - thanks!
Mastodon devs were clearly aware of the quality of text people tend to write online. It’s a very fitting term IMO.
A mastodon, like an elephant, has a trunk it can sound like a trumpet.
A toot

it’s like someone looked at the word tweet and thought “how can i make this infinitely worse?”… i hope it never catches on. I don’t know why people want their posts and announcements to sound like farts.
There is a bigger history on this. Involving the Mastodon developer Gargon and a famous YouTuber Hbomberguy:
https://mastodon.social/@Hbomberguy/146524
Gargon, at that time wasn’t aware of the double meaning, as they where non-native English speaker.
It got changed back to “publish” relatively recent.
Personally I liked “toot” it was unique and funny. Many Mastodon-Users still prefer or use “toot”.
if hbg had anything to do with it I have no choice but to retract my objection
If you don’t like the term “toot” it’s fine, it shouldn’t matter who coined it. Don’t make your likes or dislikes dependent on who stuff or ideas come from.
I just wanted to explain some history of that term.
The knowledge of that history and context is what should influence your taste, not the specific individuals involved.
I thought the begrudging tone would make it obvious but I was joking. so was hbg by the way; he clearly said it because it would be ridiculous, not because it would be smart. it’s fucking dumb.
Its catchy and funny and everyone remembers it once you tell them. In other words, its perfect.
we can call them sharts. it satisfies all the criteria.
No, no. The fedi toots with short videos are sharts.
Personally, I like to browse my feed of sharts before I go to bed.
we finally found a slogan.
“care for a shart in bed before you sleep?”
Nah, that’s not very realistic. Once you start shart scrolling, its hard to stop at just one shart
It varies from where you’re from, where i am nkbody uses it (or even knows it refers to) farting
As far as I’m aware most instances no longer refer to them as “toots” and instead refer to them as posts. Likely because “toot” is used in some places to refer to farts.
Perhaps if they made decisions like this more often in recent times there would be more people there when they do good stuff.
Edit: Cool to see someone botting this thread as well. I have now watched on three separate occasions someone vote up on mine and others comments only for a vote down to be applied within 10 seconds - 5 minutes in lockstep each time. This was in the first 15 minutes of the comment being posted.
2nd Edit. I’ve watched it happen 8 times now actually. I wonder what the odds are that over the course of ~2 hours there is exactly 8 people who agree and exactly 8 who don’t who keep showing up within moments of one another.
You mean like isolating cookies?
Like integration state partitioning for the entire browser context, user-controllable?
Like adding vertical tabs?
Like background wallpaper options for new tab independent of themes?
Like site translations?
Like working on tab groups?
Like working on tablet UI options?
Like … okay I’ll stop.
Like with red traffic lights vs green traffic lights, always keep in mind that your brain does not want to actively notice/recall things going well. It’s when things are annoying/interrupting that you remember.
No, not like that! JUST LET ME BE HATEFUL FFS
Vertical tabs? I’ve been using an extension for that so I didn’t even notice. Is that already on the main release or still on the nightlies?
Sorry for asking here but a DDG search just turns out a bunch of pages telling you how to get them with extensions, which I already do.
Its still experimental, (in nightly), and a bit unpolished so id stick with the extensions for now
I use it but…keeps waiting for jxl
I’m jealous of Safari users
Any sites out there even serving JXL? With a “global usage” of 13%, I don’t see many developers wasting their time on it unless there’s some niche use case that requires it.
Hard to use without browser support
Thanks.
Like adding vertical tabs?
Having fucked an entire ecosystem of UI-modifying plugins, seven years prior. Still not matching the functionality of that decades-running, userbase-driven experimentation. I want my goddamn multi-row tabs back.
Mozilla doesn’t get kudos for tiny improvements as if they cancel out huge blunders. Killing vertical tabs by killing XUL also severely limited DownThemAll, and they spent a year ignoring pleas from the guy that gave their browser and their browser alone the best download plugin to-date. He eventually managed to “just rewrite!” and claw most functionality back from Chrome’s tightassed tool-kit. Most authors did not. Most authors had not, since the browser fucking launched. I can barely remember how much functionality I’ve lost, thanks to Mozilla refusing to respect plugin devs and formalize any lasting API. The best bits did come back, thanks to other authors who also missed those features… until they too burned out and fucked off.
But hey! Mozilla also made some clever tweaks inside the only software project that advertises their true passion for smartphones I mean chat I mean crypto I mean AI I mean $nextbigtrend, so it’s squaresies.
All I intend to say is that if I left when Mozilla thought it was a good idea to have an advertising company become involved in the development of their products and started tracking users without their consent (even if less invasively than cookies) with PPA, then surely I am not the only one who left.
This is a company that has previously sideloaded an extension into the browser without user permissions because of a marketing deal they made with a television show. As a result, I’m afraid im less concerned with the not-yet implemented features they may be working on or the features they have in place when there are a litany of other browsers available which don’t fuck around with user permissions and privacy for advertising deals.
If I wanted a browser for tab grouping and UI stuff, I’d move to vivaldi, but at the moment firefox just doesn’t seem to have the best UI or the best security and both of those are directly related to Mozilla’s choices.
You are certainly entitled to your opinion and it is valid, but I think that my criticisms are also valid and are not baseless.
Oh for sure criticism is valid, but it’s funny how people always forget all the actual good stuff being added, too.
In general, not just Firefox-specific. People constantly forget how while Google search results have gone to shit, empyrical analysis showed that it went to shit more for other search engines (meaning if anything Google got comparatively better, but of course everyone got worse across the board, too). People constantly forget over all their little issues how some countries, including mine, have swapped >50% of their energy (from ~0%) to green energy in just 10 or so years. It’s too easy to see only the negative things.
Yes, it’s true that some good things have been added, I suppose my concern is just that I feel the negative things in the case of firefox hold greater weights when compared to the positive things they have done.
As a euphemism; a cruise ship adding a bowling alley, better seating, and fine art to its interior is neat and might make it look better and more convenient but it doesn’t mean much to me if they also added an engine which spews 50% more pollution into the atmosphere and poisons me.
No clue. I doubt it’s a conspiracy, though. Just seems like a controversial take.
Certainly possible but I’m sure the odds are astronomically low. After I saw this happen 3 times I started refreshing every minute and each time there was a change, both counts had increased, and this happened 8 times in a row. I could see a distribution happening of something like a vote up at minute 2, vote down at minute 3 vote up at minute 12, vote down at minute 20, etc, but this was - vote up and vote down at minute 5, same thing at minute 11, same thing at minute 16, etc, 8 times concurrently (the minutes listed here are an example, I wasn’t tracking exact time between events).
Im pretty sure you’re seeing a pattern where there isnt one, your post is just controversial
As I said, certainly possible, I was just surprised by the distribution over time, not the distribution of vote type.
Just so you know, some of us actually read through a chain of comments first, trying to get the full argument before making judgements, and then go back and upvote and downvote all the comments quickly in a row. So, that might seem like a bot doing it at the same time, but its just someone batch voting after reading.
To make it clear what I am talking about - I would expect any voting distribution for 16 votes to be at least semi-random on a controversial comment, in example such as this:
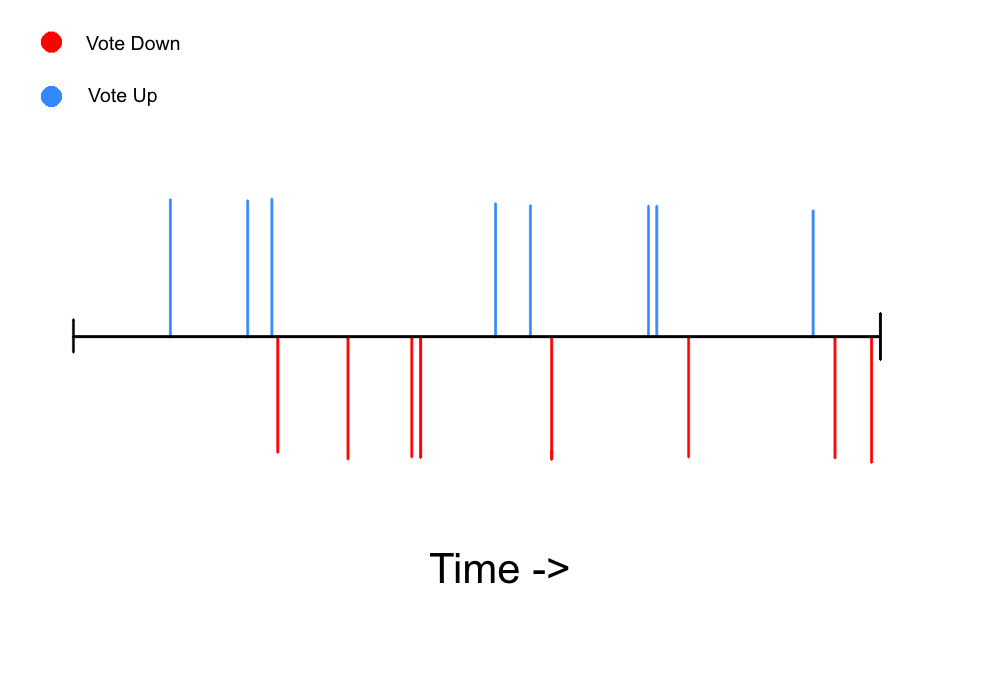
However, the distribution as it occurred looked like this on the first 16 votes:

A controversial comment will have such a ratio, but any comment controversial or not will almost never have this kind of distribution unless there are multiple accounts waiting for vote up events to occur so that they can send a vote down.
I can believe this happening 2, 3, even 4 times by chance, but not 8 times.
I’m entirely aware, I’m specifically referencing my top level comment which at the time had no replies.
Additionally, what you are describing does not explain both a vote up and vote down, occurring at the same time 8 times consecutively, so I’m not quite sure I understand what your point is as what actions occurred prior to hitting the button doesn’t enter into what I’m describing as far as I can determine.
Even if people read a thread before scrolling back up and hitting the up or down button, them hitting that button at the same time as someone else hitting the opposing button 8 times in a row within a few moments of each other is still a statistical anomaly.
See my other comment in which I graphed what I am talking about in order to better explain myself.
There were 10 or so no content account downvoters that I just banned, but also a lot of genuine downvotes.
Thanks Dessalines!
I reported their comment for suspected downvote manipulation earlier and requested the admins investigate the votes. Now I came back and 10 of the downvotes were slashed off of it. So it seems like those ‘astronomically low odds’ turned out to be at least partially correct. Otherwise why would the admins have slashed 10 downvotes from the post. It feels like the odds that 10 people had a change of heart are more astronomically low than the more likely reason which is that they got their votes slashed and their accounts banned by the admins due to an investigation finding them to be downvote bots or downvote trolls.
Fascinating, didn’t know moderators could investigate such things effectively (I was unaware of any mod tool that made that easy to do).
Its early so I only had time to take a cursory glance and the vote counts were still looking the same to me - which one had the votes removed after your report?
Good to hear nonetheless, definitely felt something was up, thanks!
Well it’s actually only Admins and instance-level moderators who can do it at the current time. Regular community mods can’t see them or pull them up, at least not in the current version of Lemmy.
It was his main comment which had the votes slashed, it was sitting at -40 but was slashed to -30. Speaking in terms of raw downvotes not just score. The +42 score it had didn’t change at all.
I see, thanks!
Meanwhile me with my Freezed Firefox version…
“So what crazy stuff is going to be discussed in arkenfoxe’s Github repo this time?”
deleted by creator
One good thing doesn’t even outweigh one bad one. What do you call someone who tells 99 truths and one lie?
A liar.
It’s the same here; there’s an asymmetry between doing what’s right and betraying someone’s trust. When Mozilla can demonstrate consistent integrity, maybe I’ll stop using a fork.
How did they betray you or their mission?
With introduction of even more AI services to Firefox I wanted to express that to me it does seem like Firefox is missing with development of features. This sentiment is echoed by a lot of people in my social bubble of technologists, ethicists and other people with same priorities as what one could think are values which Firefox was built on.
Those concerns are in my opinion very valid. The machine learning models have shown to be unreliable - just some of the recent examples from AI products made by large corporations: pointing users to eat pizza with glue, providing false information about just about anything. There are a number of ethical issues yet to be resolved with usage of AI, from its intense usage of computing resources that adds up to electric grid demands. Through privacy and possible copyright violations of datasets that power the models. To an entire bag of other issues monitored by excellent resources such as AIAAIC repository.
AI/Machine learning is an amazing field with many likely applications, and yet, its recent rise to fame is characterized by failures and issues in many implementations. Personally I often don’t even see whether the application of AI is truthfully necessary, in many cases a human would do a more trustworthy and fast task of information gathering than a large machine learning model.
When we compare current state of “AI”, does it reflect what Firefox stands for? Does it reflect Mozilla’s principals?
Let’s compare.
- Principle 2
The internet is a global public resource that must remain open and accessible.
LLMs are known for being a black box. Depending on our definition of “open and accessible”, LLMs can be a very free resource or a completely inaccessible black box of math.
- Principle 4
Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.
It’s clear that LLMs pose a privacy risk to Internet users. LLMs pose risk in at least two ways - because the data they are trained on sometimes contains private information due to negligent training process. In this case users of a learned model can possibly access private information. The second risk is of course usage of 3rd party services that may use information to infringe on privacy of users. While Mozilla in blog assures that “we are committed to following the principles of user choice, agency, and privacy as we bring AI-powered enhancements to Firefox”, it’s unclear how supporting such services as “ChatGPT, Google Gemini, HuggingChat, and Le Chat Mistral” helps protect Firefox user privacy. Giving users choice should not compromise their safety and privacy.
- Principle 10
Magnifying the public benefit aspects of the internet is an important goal, worthy of time, attention and commitment.
In my opinion in the process of designing AI functionalities on top of Firefox there was no evaluation on how those functionalities can benefit the public. There are a number of issues as mentioned above with the LLMs, they can be dangerous and work in detriment to users. Investing and supporting in technology of this type may lead to terrible consequences with little actual benefit.
In addition Mozilla claims:
- We are committed to an internet that elevates critical thinking, reasoned argument, shared knowledge, and verifiable facts.
I argue that AI models are the opposite to that. AI output is not verifiable. They are working against sharing knowledge by making seemingly accurate information that turn out to be false.
I ask Mozilla to reevaluate impact of AI considering all of those points. I ask on behalf of myself as well as many users that I see on Fediverse being greatly worried and frustrated with AI changes added on top of Firefox. There is certainly a lot of potential greatness that could be done with AI, but those steps must be taken responsibly.
Im glad you decided to copy-paste an overly padded ream of text instead of forming your own opinion, but sure.
P.2 All ai models used in firefox currently are fully open source.
P.4 Those models are also ran completely locally. That linked blog refers to an OPT-IN experiment that lets you choose what model you want to use, including non-privacy respecting ones, but this is left up to the user.
P.10 The two ai features currently in firefox are alt-text generation for blind people and privacy-respecting page translation, i think youd have a hard time justifying why those arent useful.
Im glad you decided to copy-paste an overly padded ream of text instead of forming your own opinion
I endorse it. Even if I didn’t, you asked, and do you received an answer.
P.4 Those models are also ran completely locally.
Wrong.
None of the models provided by Mozilla as defaults are run locally. They are all run on their own respective providers’ clouds.
P.2 All ai models used in firefox currently are fully open source.
Also wrong.
Even if we ignore the fact that Mozilla only allows you to connect to third parties that are running something in a black box, there is no such thing as open source AI, as far as I have seen. The models are always closed source black boxes. If you have downloaded a binary and cannot compile it yourself, you are not using something that is open source.
P.10 The two ai features currently in firefox are alt-text generation for blind people and privacy-respecting page translation
Which was not being discussed in the linked post. The fact you are trying to veer off topic from “how has Mozilla betrayed you” to “this particular other thing has not betrayed you” is unhelpful.
Just ask Seamus (the bridge builder) what people remember him for.
the comment is going “grrr ai” i was pointing out that the ai features currently in firefox (translation and alt-text) are local and privacy respecting. You cant just ignore things that dont fit your opinion.
second, that chatbot thing you’re crying about is OPT IN AND only in nightly, let you choose any chatbot available online, not just the ones they named, and on top of that it most likely will never make it into a non-nightly release, because theyve decided to make that kind of ai feature an extension instead.
Also, when i say that a model is open source, i am referring to the binary being downloadable and the model weights being freely available.
You clearly saw the word “ai” and decided that mozilla was as bad as google, without looking into it at all.
the comment is going “grrr ai”
You asked how Mozilla betrayed users, so let’s focus on that. I don’t care about the ways they haven’t betrayed users, in the same way I don’t care about how Seamus built a bridge.
second, that chatbot thing you’re crying about is>>> only in nightly
No, it’s in Firefox 130. I know this because I use Firefox.
it most likely will never make it into a non-nightly release
LOL
Also, when i say that a model is open source, i am referring to the binary being downloadable
This is not what open source means. If that’s the case, Microsoft Windows is open source. Go nuts.
You clearly saw the word “ai” and decided that mozilla was as bad as google, without looking into it at all.
People aren’t blindly saying all AI is bad. They were pointing at a specific thing. Do not strawman.
- Principle 2
This useless feature for what ? They implemented this because Google forcing them to do so I guess.



















{kind=link}