
19·
1 year agoDo you have Quick Tap enabled? I have mine set up to show notifications (I miss the old ability to swipe down on the rear fingerprint reader), but yours might be set up to play/pause media.

Do you have Quick Tap enabled? I have mine set up to show notifications (I miss the old ability to swipe down on the rear fingerprint reader), but yours might be set up to play/pause media.
There is [email protected], but it’s pretty quiet. You could try posting there to get some of that content going. It’s a bit of a vicious cycle, though - the lack of content drives people away, leading to less content.
I will say that even in smaller communities I find that people are quite helpful here with questions, which is great.
It does seem like the post reddit boom of interaction and growth has waned, thought, and many of the communities that were starting to grow are now much quieter than they were a few weeks ago. I think that the lemmy.world downtime for so long really drove people away, which is a shame.
If you don’t like it, don’t pay for it and use something else?
Yep! Fixed it, thanks.
For those of us who used sync for reddit regularly for years, it’s pretty cheap. But if it doesn’t fit your needs, thankfully you have plenty of other options these days!
Reminds me of the Edith Macefield house, in Ballard (Seattle, WA).
 .
.
If you’re ever in Ballard, I highly recommend the excellent cocktail bar Hazelwood, which pays tribute to her with a namesake cocktail (the Edith Macefield).
They are standard deviations, which is described in the footnote. But yeah, probably better to label that axis.

A farmer coughs in your face, and then you slowly get sick and eventually die.

How am I going to play my favorite game of “will lens show up” now??

I agree that these changes have all been incredibly stupid and devalue one of the few remaining producers of quality TV (HBO), but I think that this is missing the point. The key is this:
Notably, the loss in subscribers didn’t seem to affect streaming revenue. It grew to $2.73 billion this quarter, marking a 13 percent increase.
In other words, fill up the service with cheap / easy to produce reality crap and hike up prices over time. Revenue goes up and costs go way down. People drift away but you keep growing the bottom line, at least for now. The shareholders rejoice and the consumers lose.
I don’t mind it as much, but the wallpaper thing is poorly executed. I have a color photo as my lock screen and a plainish lightly textured background on my home screen. But material you picks colors from the lock screen photo, which I don’t see 99.9% of the time!

This screenshot is from earlier today, but i still get the error on the most recent beta. Was able to buy ad-free though, oddly enough.
I also am trying to purchase Ultra but can’t. Different issue, I think - I am USA based - but I keep getting this error message:


Yeah - though I had thought that still the one should be higher than the other, even if the numbers are small. In the actual equation, this would be multiplied by a scaling factor of 10000, though. (See the code discussion in the other comments). Though, in this case, the rank would still be very close to zero.
What I had missed is that, in the actual code, the equation is wrapped in floor() and returns an integer. So both are treated as rank = 0 and maybe randomly sorted.
The question is why are rank 0 posts showing up at all? In my other comment, if you do the math, I think that it should take quite a bit of time for any post with an appreciable score to decay to a rank of zero. Yet we see that these sorts of old posts are appearing relatively high in the hot feed.
One possible answer was suggested in another comment – it may have to do with how often the scores are recalculated for older posts, and if some have not decayed to zero by the time that the score recalculation stops, they might persist with a non zero score until the instance is restarted. I’m still not sure that that is the right answer, however, because I am guessing that instances like lemmy.world (which I am using) have been restarted recently with the various hacking attempts?
Can someone who knows PL/pgSQL help parse this line:
return floor(10000*log(greatest(1,score+3)) / power(((EXTRACT(EPOCH FROM (timezone('utc',now()) - published))/3600) + 2), 1.8))::integer;
It seems to me that the issue might be that the function returns an integer. If the scaling factor is inadequately large, then floor() would return zero for tons of posts (any post where the equation inside floor() evaluates to less than one). All of those posts would have equivalent ranks. This could explain why we start seeing randomly sorted old posts after a certain score threshold. Maybe better not to round here or dramatically increase the scaling factor?
I’m not sure what the units of the post age would be in here, though. Probably hours based on the division by 3600? And is log() the natural log or base 10 by default?
In any case, something still must be going wrong. If I’m doing the math correctly, a post with a score of +25 should take approximately 203 hours (assuming log base 10) before it reaches a raw rank score of < 1 and gets floored to zero, joining all of the really old posts. So we should be seeing all posts from the last 8.5 days that had +25 scores before we see any of these really old posts… But that isn’t what’s happening.
Yeah - agreed. I don’t know the best solution. The other issue is whether the algorithm is being applied to all feeds and communities in the same way. The experience will be quite different if browsing all on a highly federated, high activity instance, compared to just looking at your subscriptions or browsing a lower-activity single community. Maybe the answer is just in general to decrease the steepness of the curve.
After all of this, I will amend my response to say that I think that there must be something going wrong with the algorithm. Consider these two consecutive posts on my “hot” feed:
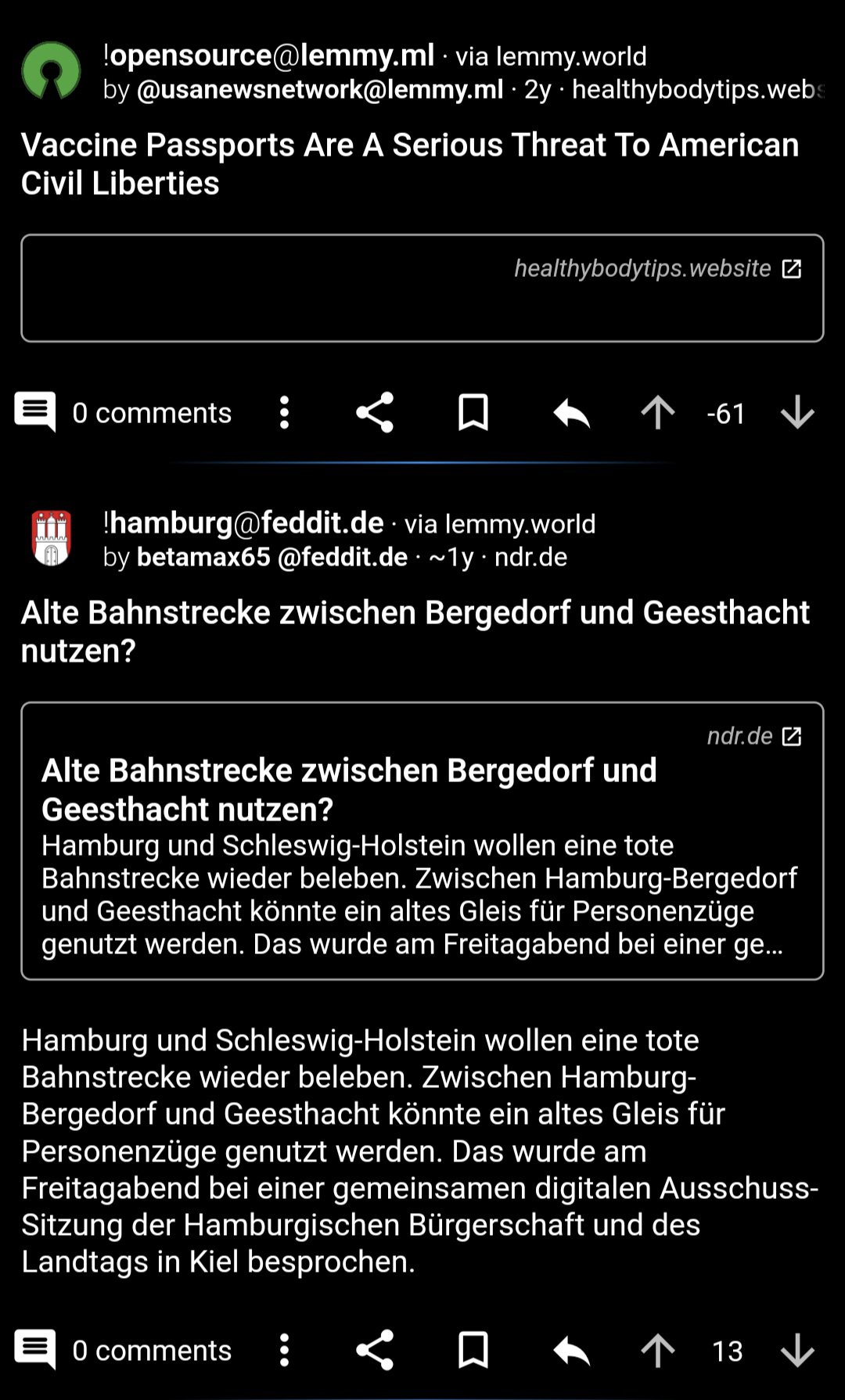
The anti-vax nonsense from two years ago was appropriately downvoted to hell. The post right underneath it is one year old and has a post score of +13. Based on the equation above, the lower post must have a higher rank than the anti-vax post, as it should have both a higher numerator and a lower denominator.
Time for a review of the source code? Or am I missing something? Do other people see this phenomenon? No older, lower-scored post should be above a newer and higher-scored post in your feed, I think.
And this picture helps too: shows the decay in ranking scores for posts of different popularity (score) over time.
![]()
After a day or so, the curve flattens out. This probably explains why we keep seeing posts that are months old in “hot” - if not enough new material is being posted, after the first few pages of “hot”, posts that are 5 days old and 5 months old are essentially the same due to the exponential decay function that was chosen.
That page gives this equation:
Rank = ScaleFactor * log(Max(1, 3 + Score)) / (Time + 2)^Gravity
Score = Upvotes - Downvotes
Time = time since submission (in hours)
Gravity = Decay gravity, 1.8 is default
My guess is that the “gravity” parameter is the issue at the moment. Something is needed to make the decay less steep, so that really old posts aren’t making it up to the top of the feed.
There might be some way of tuning the gravity parameter dynamically based on how much content is being submitted, perhaps aiming for something like “the average age of the first 200 posts should be 10 days” (I made those numbers up, but the basic idea would be that the time decay should be steeper when lots of content is submitted and less steep when content is infrequent?)



{kind=link}
{kind=link}
Yeah, I barely use quick tap. The swipe down was so intuitive, and with a bigger phone triple tapping requires you to rebalance the phone in your hand, etc.